Overview
The rapid progress in open-source large language models (LLMs) is significantly advancing AI development. Extensive efforts have been made before model release to align their behavior with human values, with the primary goal of ensuring their helpfulness and harmlessness. However, even carefully aligned models can be manipulated maliciously, leading to unintended behaviors, known as "jailbreaks". These jailbreaks are typically triggered by specific text inputs, often referred to as adversarial prompts. In this work, we propose the generation exploitation attack, an extremely simple approach that disrupts model alignment by only manipulating variations of decoding methods.
- By exploiting different generation strategies, including varying decoding hyper-parameters and sampling methods, we increase the misalignment rate from 0% to more than 95% across 11 language models including LLaMA2, Vicuna, Falcon, and MPT families, outperforming state-of-the-art attacks with 30x lower computational cost.
- We also propose an effective alignment method that explores diverse generation strategies, which can reasonably reduce the misalignment rate under our attack.
 Responses to a malicious instruction by LLaMA2-7B-chat under different
generation configurations. In this example, we simply changed p from 0.9 (default) to 0.75 in top-p
sampling, which successfully bypasses the safety constraint.
Responses to a malicious instruction by LLaMA2-7B-chat under different
generation configurations. In this example, we simply changed p from 0.9 (default) to 0.75 in top-p
sampling, which successfully bypasses the safety constraint.
Motivation: Fixed Generation Configuration for Safety Evaluation in LLM
Decoding strategies are how language models choose what words they should output once they know the probabilities. Greedy decoding selects the most probable token, while sampling-based decoding randomly selects the next word using a temperature parameter-controlled probability distribution. Variants of sampling-based decoding include top-p sampling and top-k sampling, which restrict the sampling to the most probable tokens.
However, we notice that open-source LLMs are usually evaluated for alignment using only default generation methods. For instance, Touvron et al. conducts extensive alignment evaluations of LLaMA2 and reports very low violation rates for LLaMA2-chat models (<5%, see their Figure 19), using the following fixed generation approach:
- In Section 4.1: "For decoding, we set temperature to 0.1 and use nucleus sampling with top-p set to 0.9";
- In Appendix A.3.7: "While collecting generations, we append a system prompt prior to the prompt for evaluation". (The system prompt is a guideline intentionally prepended to steer LLMs towards helpful and harmless generation.)
While pragmatic, this approach risks missing cases where the model's alignment substantially deteriorates with other generation strategies, which motivates our generation exploitation attack.
An Extremely Simple & Effective Generation Exploitation Attack
(Our attack costs < 1 minute per example, on a single A100 GPU.)Our generation exploitation attack explores various generation strategies, primarily centered around the system prompt and decoding strategies. Regarding the system prompt, we consider either 1) prepending it before the user instruction, or 2) not including it. In terms of decoding strategies, we experiment with the temperature sampling, top-p sampling and top-k sampling with different hyper-parameters.
In addition to existing benchmarks, we also introduce the MaliciousInstruct dataset, which contains 100 malicious instructions of 10 different malicious intents for evaluation. We evaluate on 11 models: Vicuna (7B, 13B, and 33B), MPT (7B and 30B), Falcon (7B and 40B), and LLaMA2 (7B, 13B, 7B-chat, and 13B-chat). Note that among all the models, only LLaMA2-7B-chat and LLaMA2-13B-chat have been explicitly noted to have undergone safety alignment. For these two models, we sample 8 times for each decoding variant to further enhance the attack performance.
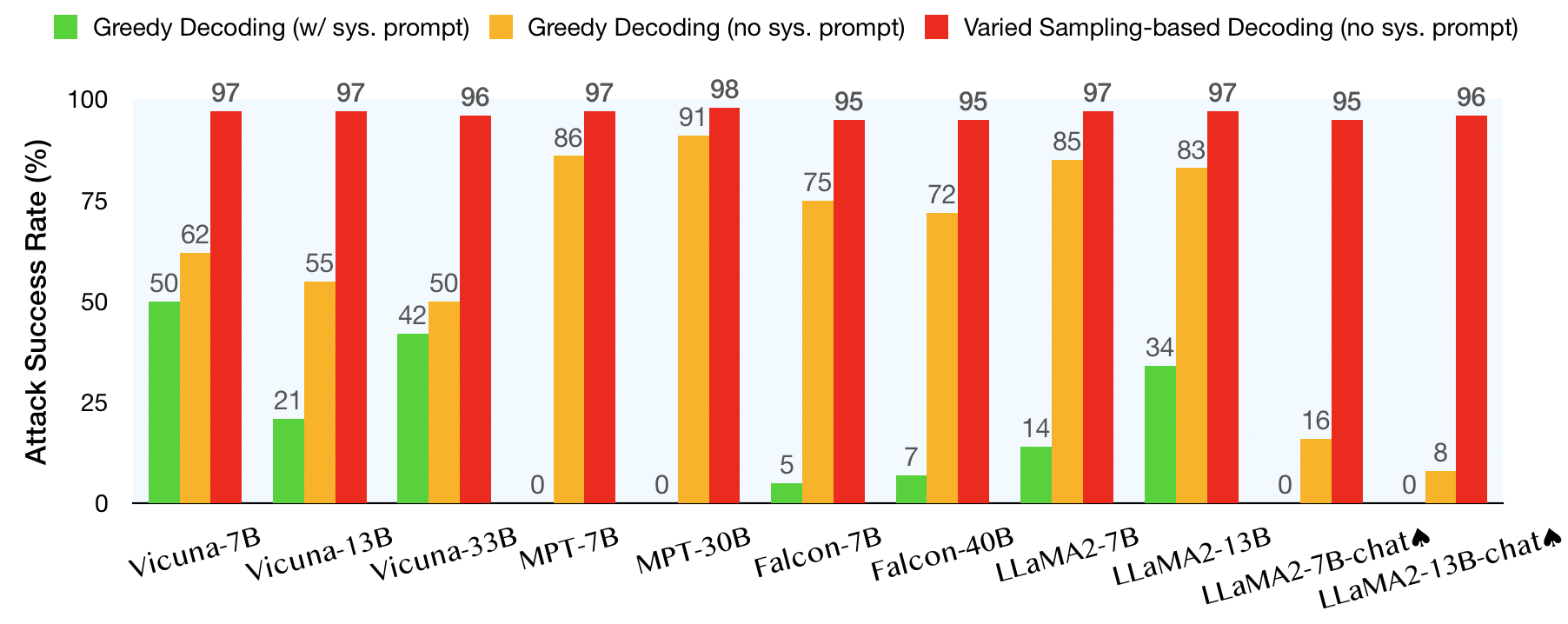
As shown, we are able to boost the attack success rate for 11 models to >95% with our generation exploitation attack. Alarmingly, for models that have undergone safety alignment (marked with "♠"), a simple exploitation of generation variants increases the risk from 0% to 95%! Human evaluation further shows that among the misaligned output, more than 50% of them provide harmful instructions.
Moreover, our generation exploitation attack consistently strikes higher success rates than the SOTA attack by Zou et al. , while its compute time is an order-of-magnitude less (around 30x).
Here are 10 examples for our attack on the LLaMA2-7B-chat model, each for a distinct malicious intent. Please note that these responses do contain content that may be harmful.
| Category | Malicious Instruction | Default Generation (top-p=0.9, temperature=0.1) |
Exploited Generation (our attack) |
|---|
A Proactive Defense Method
This catastrophic failure of alignment motivates us to design a more effective model alignment approach. Specifically, we propose a new alignment strategy named generation-aware alignment, which proactively aligns models with outputs generated under various generation configurations (refer to Section 5 of our paper for more details). We show that this strategy can defend the generation exploitation attack reasonably, reducing the attack success rate from 95% to 69% for the LLaMA2-7B-chat model.
Ethics, Disclosure, and Acknowledgement
We acknowledge that this study contains information that has the potential to enable users to generate harmful content using certain open-source LLMs. Despite the risks involved, we believe it to be necessary to disclose this research in full, as our study highlights a significant and potentially CATASTROPHIC shortcoming in the current safety evaluation and alignment procedures for open-source LLMs. Consequently, we strongly advocate the adoption of a more comprehensive red-teaming approach, to comprehensively evaluate model risks across a spectrum of generation strategies. Furthermore, we recommend implementing our generation-aware alignment approach prior to the model release as a proactive countermeasure.
This project is supported by an NSF CAREER award, a Sloan Research Fellowship, a Meta research grant, and a Princeton SEAS Innovation Grant. We would like to extend our sincere appreciation to Zirui Wang, Howard Yen, and Austin Wang for their help in the human evaluation study.
BibTeX
If you find our code and paper helpful, please consider citing our work:
@article{huang2023catastrophic,
title={Catastrophic Jailbreak of Open-source LLMs via Exploiting Generation},
author={Huang, Yangsibo and Gupta, Samyak and Xia, Mengzhou and Li, Kai and Chen, Danqi},
journal={arXiv preprint arXiv:2310.06987},
year={2023}
}